new
improved
Introducing AI Speakers
A major advancement in speed & quality of AI speech
With our new Al voice model, training
AI speakers
only requires a few seconds of audio. Plus, our enhanced text-to-speech and Overdub generation make your Al speech sound more natural and convincing than ever.Along with a fresh, user-friendly interface, the reimagined Al Speakers marks a new era of simplified speaker label management, an easier write mode experience, along with other exciting changes.
Dive into our comprehensive
transition guide
to swiftly master what's new and enhanced.AI Speakers also marks the first release in a series of upcoming AI feature drops over the coming weeks. Stay tuned for more!
Terminology changes
- Speakers—we’ve renamed the term Speaker labels to just Speakers. Now, Speakers represent the labels in a project, simplifying the identification of speakers and management of voices in your projects.
- AI Speakers—When Speakers have speech generation enabled on them (adding a Voice clone), they graduate to an AI Speaker.
- Text-to-speech—this term refers to the process of writing new text in your Composition with an AI Speaker selected.
- Overdub—this term now only refers to the process of replacing pre-recorded speech audio using an AI Speaker.
- AI Speakers tab—this tab in the Drive view was formerly known as the Voices tab.
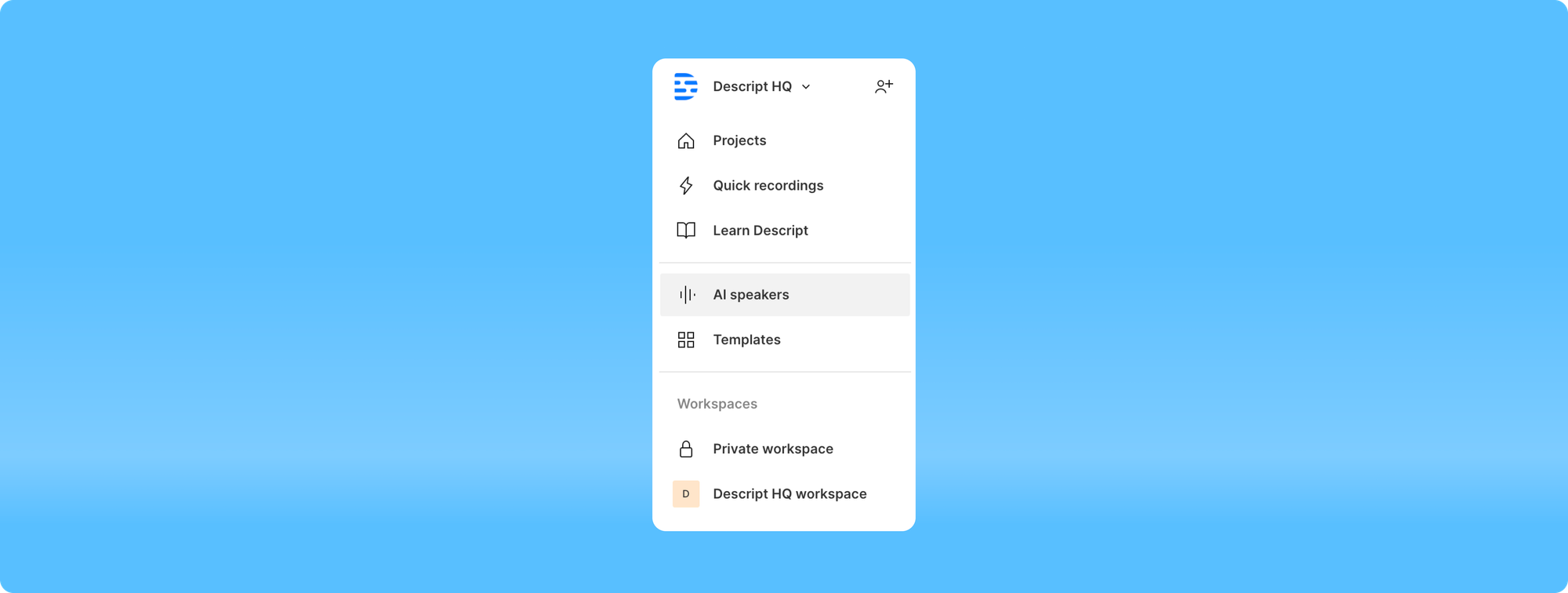
Instant speaker creation
- Eliminated the necessity for >10-minute training projects to create speakers, now it takes just around 30 seconds of audio
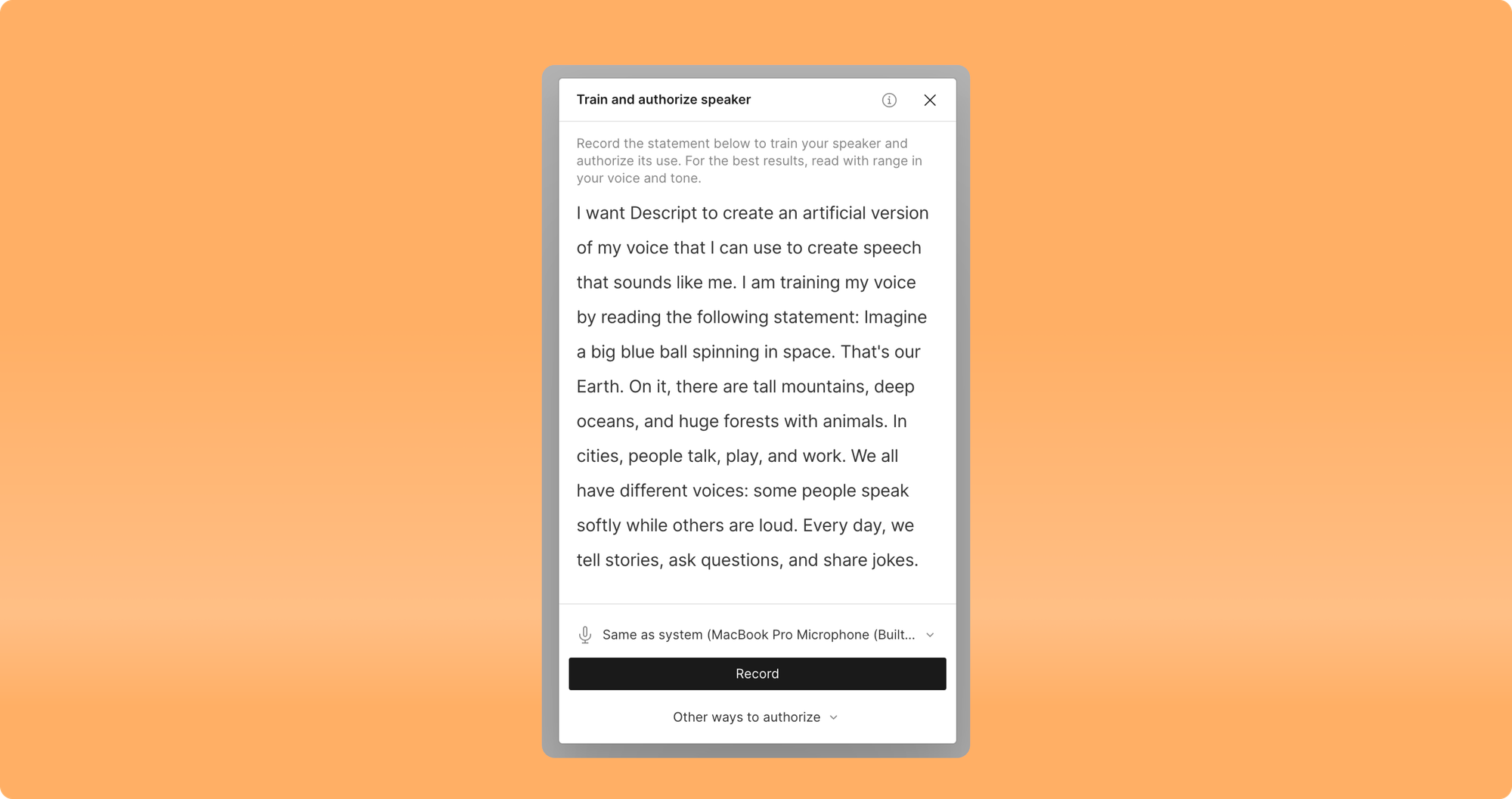
- It no longer takes up to 24 hours for verification, it now takes under a minute
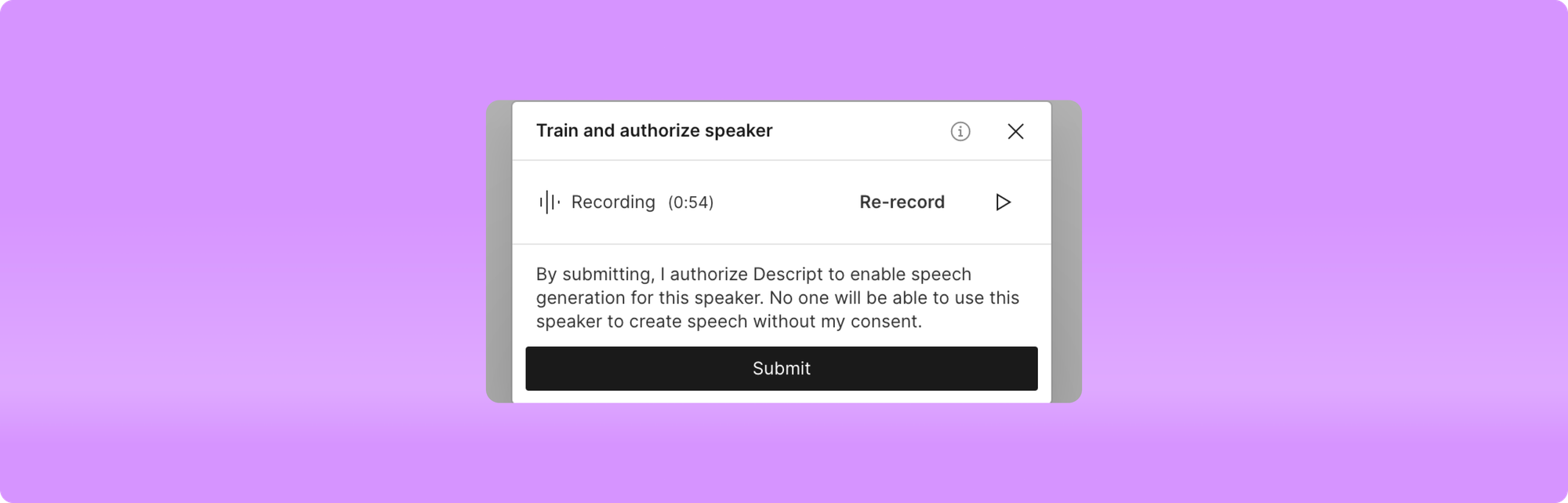
- New user experience for adding new speakers in the AI Speakers view
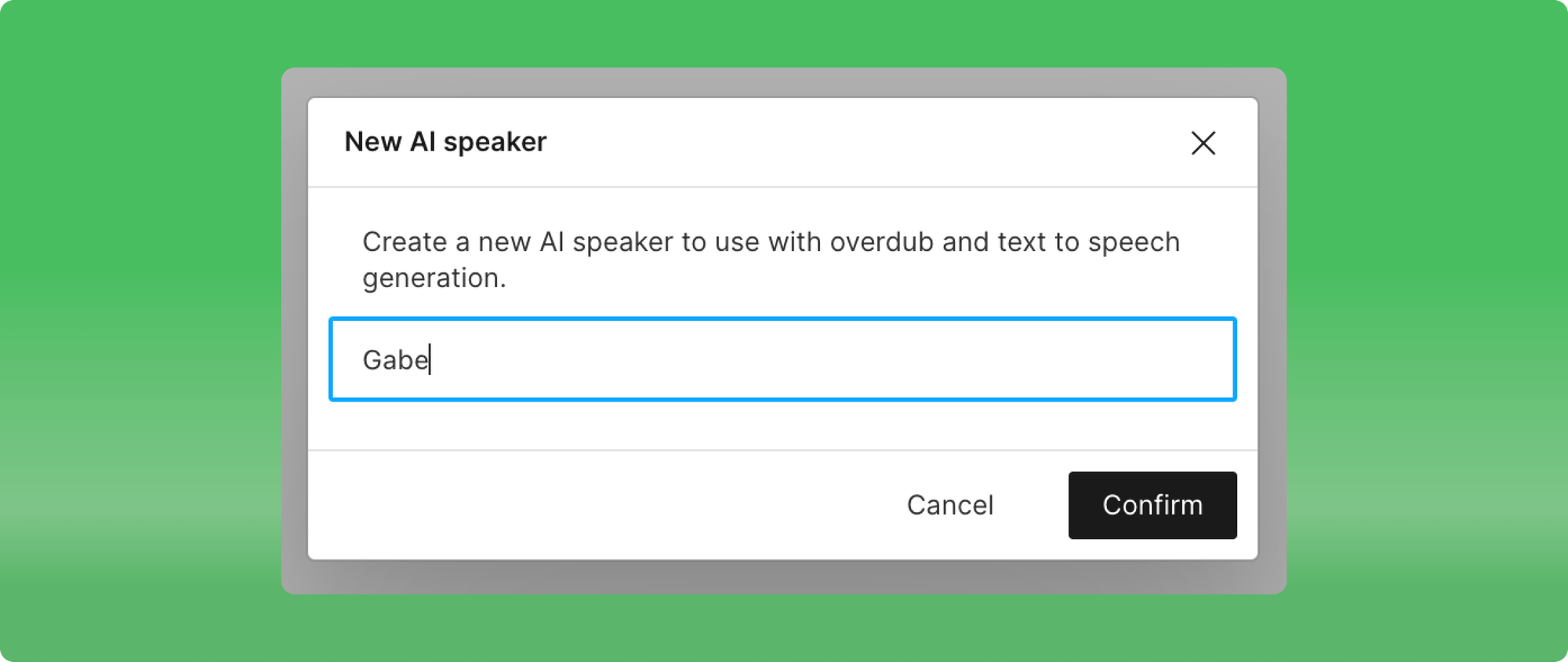
- New ways to create or use an AI Speaker from inside projects
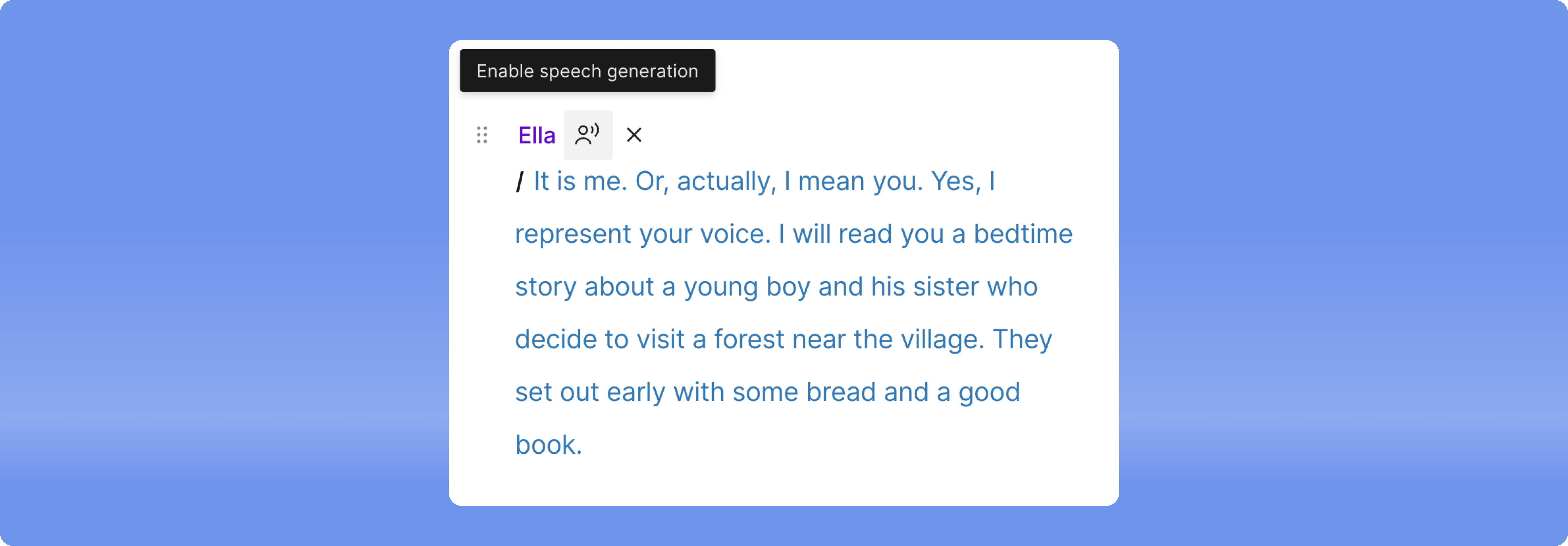
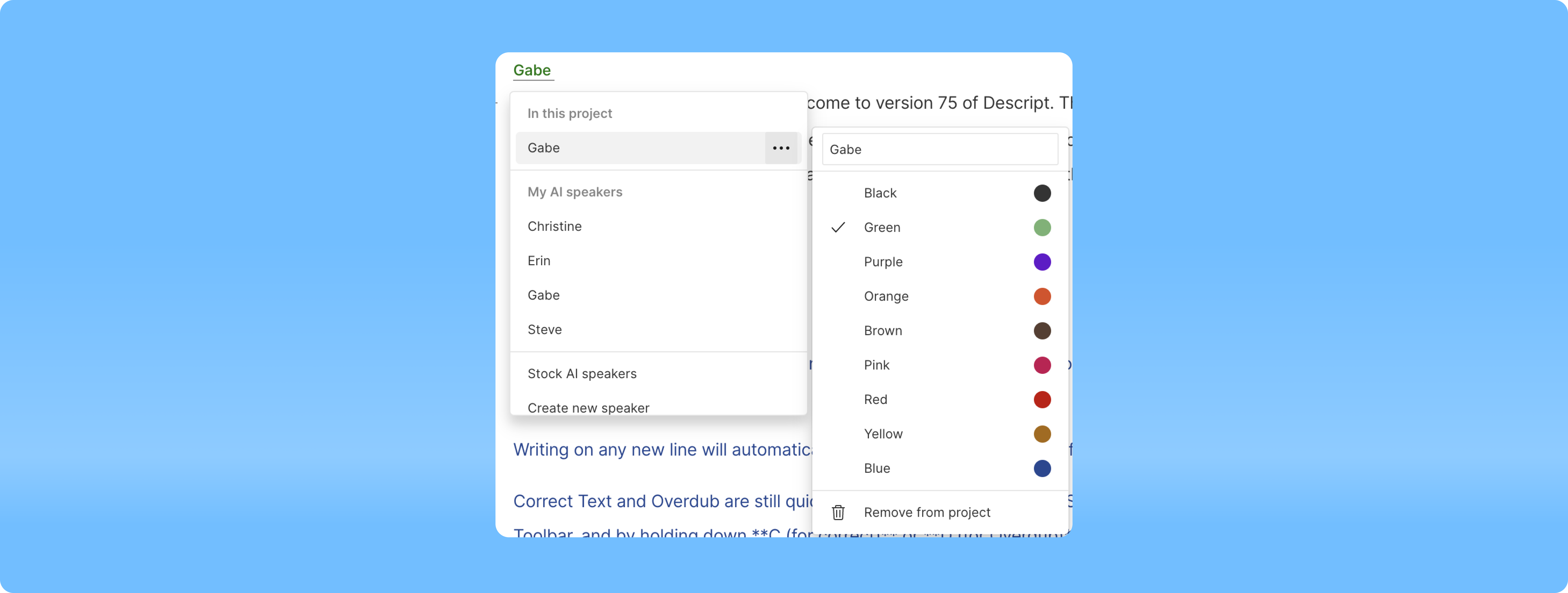
Speaker label dropdown revamp
- Speaker management is now fully integrated into the speaker label dropdown, eliminating the need for a separate modal
- Functionalities include creating, selecting, and renaming directly from the speaker label dropdown
Overdub generation improvements
- Overdub is now generated using the surrounding audio in the document to ensure that the new speech sounds exactly like the speaker in the recording
- Enhanced verification to ensure the training statement voice matches the surrounding audio in the document for Overdub generation
Text-to-speech quality improvements
We’re now smarter about when to generate text-to-speech so it will generate more immediately, and only when you want it to
- We don’t autogenerate while you’re typing in Write mode, so no more time pressure! If you make edits that aren’t covered by these triggers, we will still catch them but on a slower interval
- Paragraph-by-paragraph generation replaces sentence-by-sentence generation for more natural speech flow within a paragraph
Other notable changes
- Write mode: We’ve simplified script modes down to just the single Write mode. And AI Speech is now generated primarily when exiting write mode. You can now toggle in and out of Write mode with Cmd-E.
- Auto-generation of speech now occurs every 10 seconds instead of every 5 seconds in Edit mode, with no auto-generation in Write mode.
- Speech generation triggers on playback, exiting Write mode, or if the AI Speaker changes